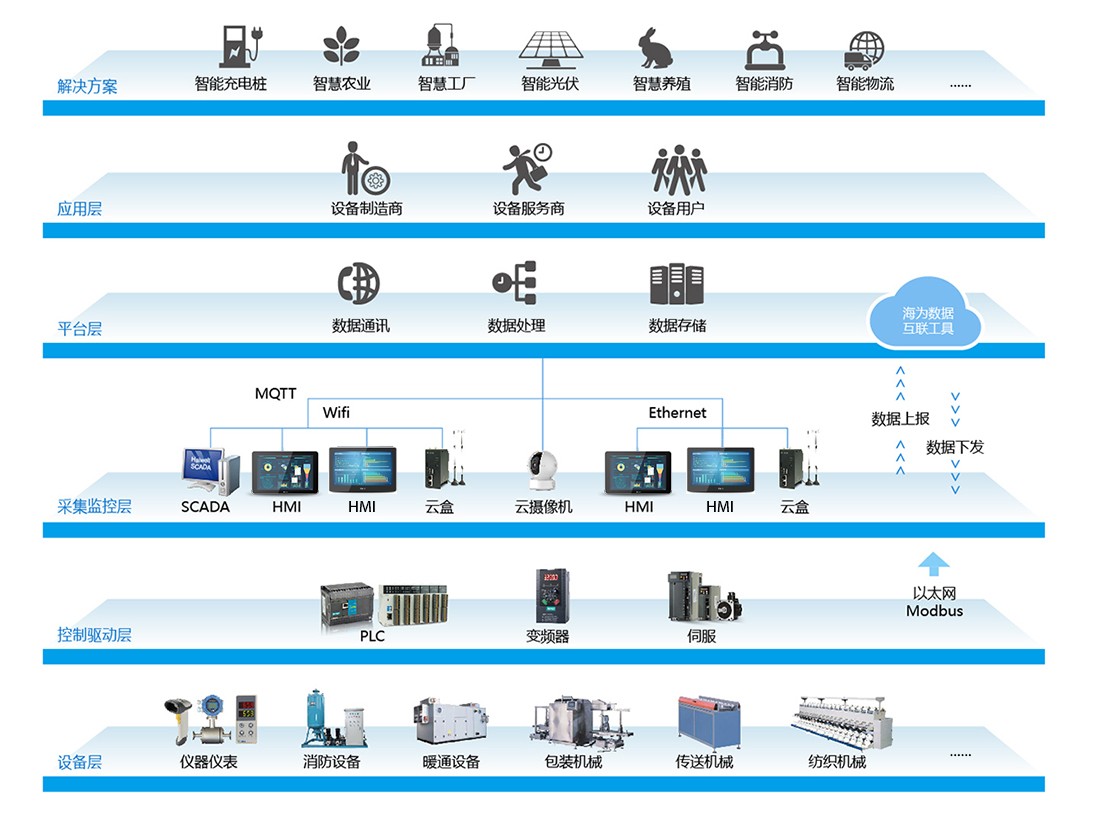
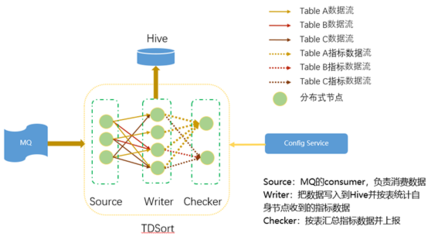
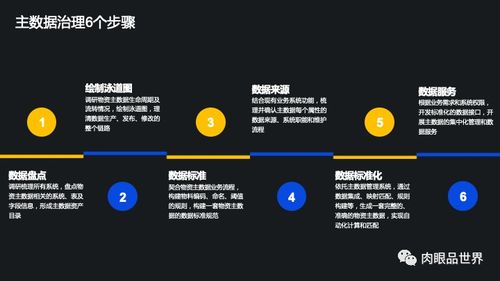
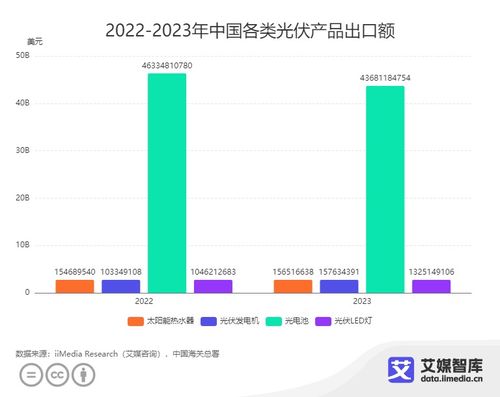
數(shù)據(jù)處理的基本功 正確采集、清洗與富集
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,無(wú)論是企業(yè)的商業(yè)決策、科研項(xiàng)目的深入探索,還是日常運(yùn)營(yíng)的效率優(yōu)化,都離不開(kāi)高質(zhì)量的數(shù)據(jù)支持。而高質(zhì)量數(shù)據(jù)的誕生,并非一蹴而就,它依賴(lài)于一套嚴(yán)謹(jǐn)、專(zhuān)業(yè)的數(shù)據(jù)處理流程。這其中,數(shù)據(jù)采集、數(shù)據(jù)清洗與數(shù)據(jù)富集構(gòu)成了數(shù)據(jù)處理服務(wù)的三大基本功,它們環(huán)環(huán)相扣,共同為后續(xù)的分析與應(yīng)用打下堅(jiān)實(shí)基石。
一、 正確采集:確保數(shù)據(jù)來(lái)源的可靠與合規(guī)
數(shù)據(jù)采集是數(shù)據(jù)生命周期的起點(diǎn),其核心在于“正確”二字。這不僅僅意味著技術(shù)上的準(zhǔn)確抓取,更關(guān)乎策略的合理性與過(guò)程的合規(guī)性。
- 明確目標(biāo)與范圍:在采集之前,必須清晰定義需要什么數(shù)據(jù)、為什么需要,以及數(shù)據(jù)的邊界在哪里。這能有效避免采集工作的盲目性與資源浪費(fèi)。
- 選擇可靠來(lái)源:數(shù)據(jù)源的質(zhì)量直接決定了后續(xù)所有工作的上限。來(lái)源包括內(nèi)部業(yè)務(wù)系統(tǒng)、外部公開(kāi)數(shù)據(jù)庫(kù)、API接口、傳感器、日志文件、社交媒體等。評(píng)估來(lái)源的權(quán)威性、穩(wěn)定性、更新頻率至關(guān)重要。
- 采用合適的技術(shù)與工具:根據(jù)數(shù)據(jù)源的類(lèi)型(結(jié)構(gòu)化、半結(jié)構(gòu)化、非結(jié)構(gòu)化)和規(guī)模,選擇爬蟲(chóng)技術(shù)、ETL工具、日志收集系統(tǒng)或物聯(lián)網(wǎng)采集方案等。
- 恪守合規(guī)與倫理:在采集公開(kāi)數(shù)據(jù),特別是涉及個(gè)人隱私的數(shù)據(jù)時(shí),必須嚴(yán)格遵守相關(guān)法律法規(guī)(如GDPR、個(gè)人信息保護(hù)法)和平臺(tái)協(xié)議。合規(guī)采集是數(shù)據(jù)應(yīng)用的生命線。
正確的采集,為后續(xù)流程輸送了“原礦石”,雖然粗糙,但確保了其真實(shí)性與獲取的正當(dāng)性。
二、 深度清洗:從“臟數(shù)據(jù)”到“干凈數(shù)據(jù)”的蛻變
原始數(shù)據(jù)往往存在大量問(wèn)題,如重復(fù)記錄、格式不一、缺失值、異常值、邏輯錯(cuò)誤等,我們稱(chēng)之為“臟數(shù)據(jù)”。數(shù)據(jù)清洗的目的,就是通過(guò)一系列技術(shù)手段,將這些數(shù)據(jù)轉(zhuǎn)化為一致、準(zhǔn)確、可用的“干凈數(shù)據(jù)”。
- 處理缺失值:根據(jù)數(shù)據(jù)特性和業(yè)務(wù)邏輯,選擇刪除缺失記錄、用均值/中位數(shù)填充、或使用算法預(yù)測(cè)填充。
- 處理重復(fù)值:識(shí)別并合并或刪除完全重復(fù)或關(guān)鍵字段重復(fù)的記錄,保證數(shù)據(jù)的唯一性。
- 格式標(biāo)準(zhǔn)化:將日期、貨幣、單位等字段轉(zhuǎn)換為統(tǒng)一的格式,例如將所有日期統(tǒng)一為“YYYY-MM-DD”。
- 糾正錯(cuò)誤與異常值:通過(guò)業(yè)務(wù)規(guī)則或統(tǒng)計(jì)方法(如3σ原則)識(shí)別并處理明顯錯(cuò)誤或偏離正常范圍的異常值,判斷其是錄入錯(cuò)誤需修正,還是特殊情況需保留。
- 數(shù)據(jù)驗(yàn)證:檢查數(shù)據(jù)間的邏輯關(guān)系是否合理,如年齡不能為負(fù)數(shù),訂單金額與商品單價(jià)、數(shù)量需匹配。
數(shù)據(jù)清洗是一個(gè)迭代和需要領(lǐng)域知識(shí)的過(guò)程,其質(zhì)量直接決定了分析結(jié)果的可靠性。它如同對(duì)“原礦石”進(jìn)行篩選、破碎和提純,得到可進(jìn)一步加工的“精礦”。
三、 智能富集:賦予數(shù)據(jù)更高的價(jià)值與洞察力
數(shù)據(jù)富集是在清洗后的干凈數(shù)據(jù)基礎(chǔ)上,通過(guò)整合外部數(shù)據(jù)源或運(yùn)用算法模型,為原有數(shù)據(jù)添加新的、有價(jià)值的屬性、標(biāo)簽或信息,從而提升數(shù)據(jù)的密度與維度,使其能揭示更深層次的洞察。
- 內(nèi)部數(shù)據(jù)關(guān)聯(lián):將不同業(yè)務(wù)線條或部門(mén)的數(shù)據(jù)通過(guò)關(guān)鍵字段(如用戶ID、訂單號(hào))進(jìn)行關(guān)聯(lián),形成更完整的視圖。
- 引入外部數(shù)據(jù):結(jié)合地理位置信息、行業(yè)宏觀數(shù)據(jù)、經(jīng)濟(jì)指標(biāo)、天氣數(shù)據(jù)等,為分析提供更豐富的上下文。例如,為銷(xiāo)售數(shù)據(jù)匹配當(dāng)?shù)靥鞖夂凸?jié)假日信息。
- 衍生特征工程:通過(guò)計(jì)算生成新的特征,如從交易記錄中計(jì)算用戶消費(fèi)頻率、客單價(jià)、最近購(gòu)買(mǎi)時(shí)間等RFM指標(biāo)。
- 應(yīng)用模型與標(biāo)簽:利用自然語(yǔ)言處理技術(shù)對(duì)文本評(píng)論進(jìn)行情感分析并打上情感標(biāo)簽;利用機(jī)器學(xué)習(xí)模型對(duì)客戶進(jìn)行分群并打上群體標(biāo)簽。
數(shù)據(jù)富集是“點(diǎn)石成金”的關(guān)鍵一步,它將基礎(chǔ)的“精礦”冶煉成具有特定功能和更高價(jià)值的“合金材料”,為精準(zhǔn)營(yíng)銷(xiāo)、風(fēng)險(xiǎn)控制、智能推薦等高級(jí)應(yīng)用提供了可能。
四、 集成化的數(shù)據(jù)處理服務(wù):專(zhuān)業(yè)賦能
對(duì)于許多組織而言,獨(dú)立構(gòu)建和維護(hù)一套完整、高效的數(shù)據(jù)處理流水線成本高昂且技術(shù)復(fù)雜。因此,專(zhuān)業(yè)的數(shù)據(jù)處理服務(wù)應(yīng)運(yùn)而生。這類(lèi)服務(wù)將數(shù)據(jù)采集、清洗、富集乃至存儲(chǔ)、分析等能力進(jìn)行封裝,以平臺(tái)或定制化解決方案的形式提供。其優(yōu)勢(shì)在于:
- 專(zhuān)業(yè)性與效率:提供經(jīng)過(guò)驗(yàn)證的最佳實(shí)踐和先進(jìn)工具,快速產(chǎn)出高質(zhì)量數(shù)據(jù)。
- 成本可控:減少企業(yè)在硬件、軟件和專(zhuān)業(yè)團(tuán)隊(duì)上的長(zhǎng)期投入,采用按需服務(wù)模式。
- 聚焦核心業(yè)務(wù):讓企業(yè)能將資源集中于自身的數(shù)據(jù)分析和業(yè)務(wù)創(chuàng)新,而非底層數(shù)據(jù)處理的技術(shù)細(xì)節(jié)。
數(shù)據(jù)采集、清洗與富集,構(gòu)成了數(shù)據(jù)處理不可分割的“鐵三角”。正確的采集確保了數(shù)據(jù)的“源頭活水”,深度的清洗保障了數(shù)據(jù)的“純凈可靠”,而智能的富集則賦予了數(shù)據(jù)“遠(yuǎn)見(jiàn)卓識(shí)”。掌握這三項(xiàng)基本功,或善用專(zhuān)業(yè)的數(shù)據(jù)處理服務(wù),是任何組織在數(shù)字經(jīng)濟(jì)時(shí)代將海量數(shù)據(jù)轉(zhuǎn)化為寶貴資產(chǎn)和核心競(jìng)爭(zhēng)力的必經(jīng)之路。只有夯實(shí)了這一基礎(chǔ),數(shù)據(jù)分析和智能應(yīng)用的大廈才能屹立不倒,真正驅(qū)動(dòng)決策與增長(zhǎng)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.fuelcellstore.cn/product/20.html
更新時(shí)間:2026-06-13 16:26:29